⚡
Hybrid Attention Mechanism
Combines Lightning Attention with Softmax Attention for optimal efficiency and precision
MiniMax-M1 AI delivers breakthrough performance with 456B parameters, 1M token context length, and 25% reduced compute costs vs DeepSeek R1. This Mini Max M1 model is fully open-source under Apache 2.0 license.
MiniMax-M1 AI introduces groundbreaking hybrid attention mechanisms and MoE architecture. This Mini Max M1 model sets new standards for open-source AI models, outperforming DeepSeek R1 with superior efficiency.
Combines Lightning Attention with Softmax Attention for optimal balance of efficiency and precision in reasoning tasks.
456B total parameters with only 45.9B activated per token, delivering exceptional performance with reduced computational overhead.
Released under Apache 2.0 license, enabling unrestricted commercial use and community-driven innovation.
Advanced capabilities designed for real-world applications
Combines Lightning Attention with Softmax Attention for optimal efficiency and precision
456B total parameters with only 45.9B activated per token for efficient computation
Native 1M token context window, expandable to 4M tokens during inference
Consumes only 25% FLOPs compared to DeepSeek R1 at 100K token generation
Comprehensive performance analysis against leading models
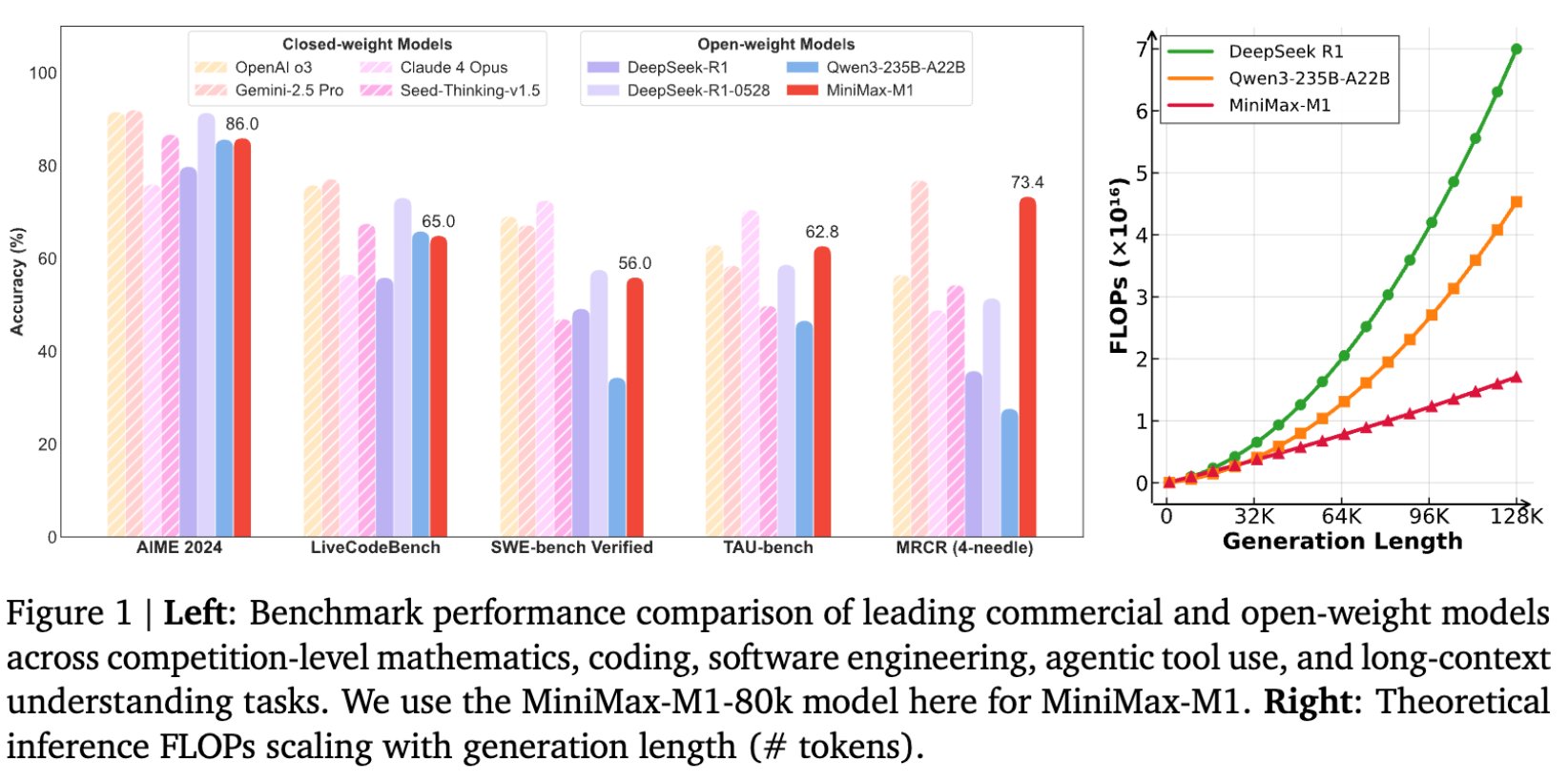
Left: Benchmark performance comparison of leading commercial and open-weight models across competition-level mathematics, coding, software engineering, agentic tool use, and long-context understanding tasks. We use the MiniMax-M1-80k model here for MiniMax-M1. Right: Theoretical inference FLOPs scaling with generation length (# tokens).
Leading performance across mathematics, coding, reasoning, and long-context tasks
Multiple deployment methods to suit your needs
Download directly from HuggingFace repository
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
Recommended for production deployment with excellent performance
pip install vllm
vllm serve MiniMax-AI/MiniMax-M1-40k
Direct deployment using Transformers library
pip install transformers torch
python -c "from transformers import pipeline; model = pipeline('text-generation', model='MiniMax-AI/MiniMax-M1-40k')"
Common questions about MiniMax-M1 and detailed answers
MiniMax-M1 AI is the world's first open-weight, large-scale hybrid-attention reasoning model. This Mini Max M1 features a unique hybrid Mixture-of-Experts (MoE) architecture combined with Lightning Attention mechanism. With 456B total parameters and only 45.9B activated per token, MiniMaxM1 offers superior efficiency while supporting 1M token context length natively, which is 8x larger than DeepSeek R1 and many competing models.
MiniMax-M1 AI is highly efficient thanks to its Lightning Attention mechanism. Compared to DeepSeek R1, Mini Max M1 consumes only 25% of the FLOPs at a generation length of 100K tokens. This MiniMaxM1 efficiency makes it particularly suitable for complex tasks requiring extensive reasoning and 1M token context processing.
MiniMax-M1 comes in two versions: M1-40K and M1-80K, referring to their thinking budgets. The 80K version offers enhanced reasoning capabilities for more complex tasks, while the 40K version provides a good balance of performance and efficiency. Both versions share the same core architecture and 456B parameter count.
MiniMax-M1 demonstrates strong performance across various benchmarks. On AIME 2024, it achieves 86.0% (80K) and 83.3% (40K). For software engineering tasks like SWE-bench Verified, it scores 56.0% and 55.6% respectively. It particularly excels in long-context tasks, achieving 73.4% on OpenAI-MRCR (128k) and 56.2% on 1M token tasks.
MiniMax-M1 can be deployed using multiple methods: vLLM (recommended for production), Transformers, or HuggingFace. The model is available on HuggingFace Hub and GitHub. For general use, you can try the online chatbot at chat.minimaxi.com or use the API for development purposes.
Lightning Attention is MiniMax-M1's innovative attention mechanism that enables efficient scaling of test-time compute. It combines with traditional Softmax Attention in a hybrid architecture, allowing the model to process extremely long contexts (up to 4M tokens during inference) while maintaining computational efficiency.
Yes, MiniMax-M1 supports function calling capabilities. The model can identify when external functions need to be called and output function call parameters in a structured format. This makes it suitable for agentic applications and tool use scenarios.
MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems ranging from traditional mathematical reasoning to sandbox-based, real-world software engineering environments. The training utilizes CISPO, a novel algorithm that clips importance sampling weights instead of token updates, which outperforms other competitive RL variants.
MiniMax-M1 is released under the Apache 2.0 license, making it fully open-source and free for both commercial and research use. This allows developers and researchers to freely use, modify, and distribute the model while maintaining attribution.
For technical support, questions, or feedback, you can contact the MiniMax team at [email protected]. You can also follow the project on GitHub for updates and community discussions.